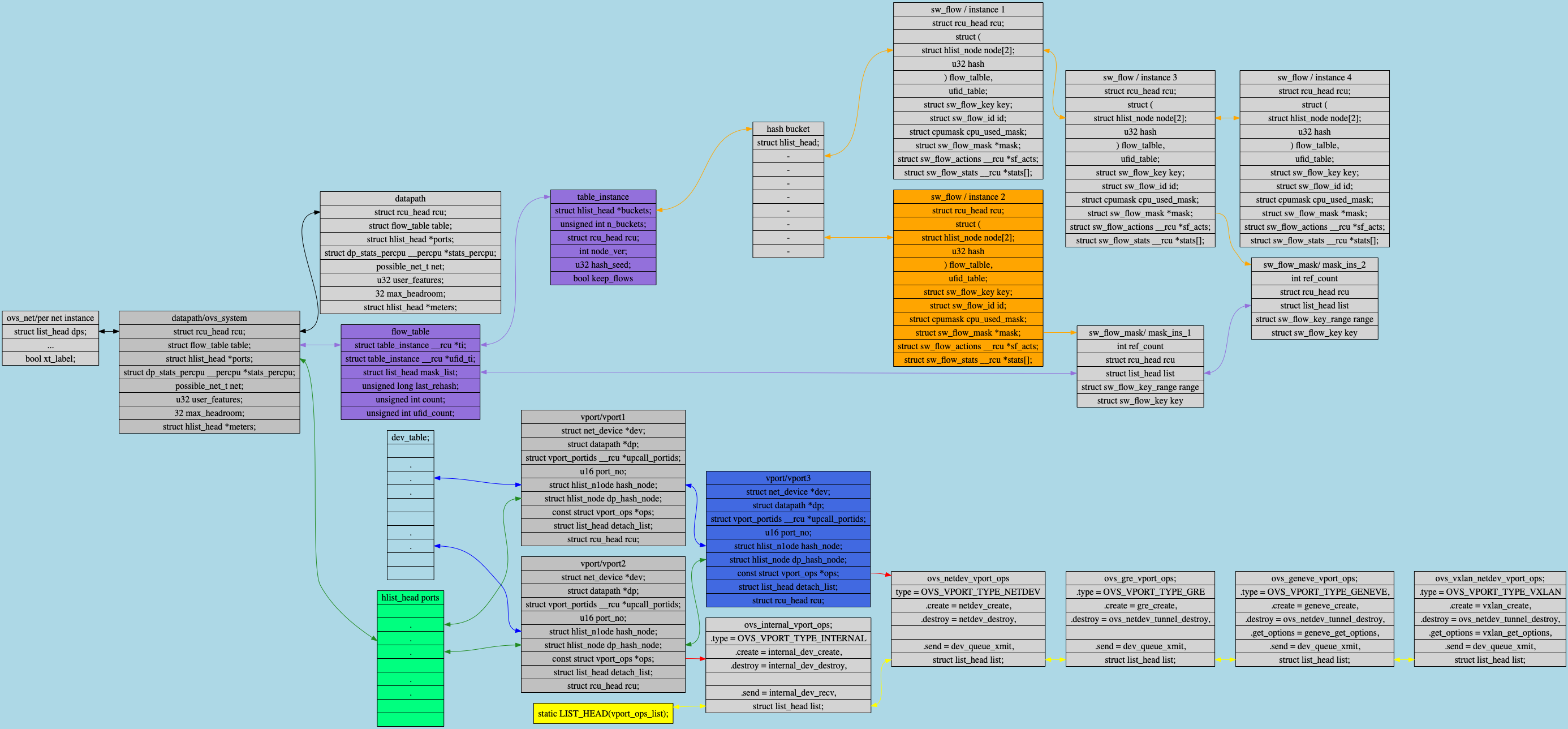
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| ➜ linux git:(master) grep inet6_add_protocol net include -Rw
net/dccp/ipv6.c: err = inet6_add_protocol(&dccp_v6_protocol, IPPROTO_DCCP);
net/l2tp/l2tp_ip6.c: err = inet6_add_protocol(&l2tp_ip6_protocol, IPPROTO_L2TP);
net/sctp/ipv6.c: if (inet6_add_protocol(&sctpv6_protocol, IPPROTO_SCTP) < 0)
net/ipv6/udplite.c: ret = inet6_add_protocol(&udplitev6_protocol, IPPROTO_UDPLITE);
net/ipv6/xfrm6_protocol.c: if (inet6_add_protocol(netproto(protocol), protocol)) {
net/ipv6/exthdrs.c: ret = inet6_add_protocol(&rthdr_protocol, IPPROTO_ROUTING);
net/ipv6/exthdrs.c: ret = inet6_add_protocol(&destopt_protocol, IPPROTO_DSTOPTS);
net/ipv6/exthdrs.c: ret = inet6_add_protocol(&nodata_protocol, IPPROTO_NONE);
net/ipv6/ip6mr.c: if (inet6_add_protocol(&pim6_protocol, IPPROTO_PIM) < 0) {
net/ipv6/udp.c: ret = inet6_add_protocol(&net_hotdata.udpv6_protocol, IPPROTO_UDP);
net/ipv6/ip6_gre.c: err = inet6_add_protocol(&ip6gre_protocol, IPPROTO_GRE);
net/ipv6/reassembly.c: ret = inet6_add_protocol(&frag_protocol, IPPROTO_FRAGMENT);
net/ipv6/protocol.c:int inet6_add_protocol(const struct inet6_protocol *prot, unsigned char protocol)
net/ipv6/protocol.c:EXPORT_SYMBOL(inet6_add_protocol);
net/ipv6/tcp_ipv6.c: ret = inet6_add_protocol(&net_hotdata.tcpv6_protocol, IPPROTO_TCP);
net/ipv6/icmp.c: if (inet6_add_protocol(&icmpv6_protocol, IPPROTO_ICMPV6) < 0)
net/ipv6/tunnel6.c: if (inet6_add_protocol(&tunnel6_protocol, IPPROTO_IPV6)) {
net/ipv6/tunnel6.c: if (inet6_add_protocol(&tunnel46_protocol, IPPROTO_IPIP)) {
net/ipv6/tunnel6.c: inet6_add_protocol(&tunnelmpls6_protocol, IPPROTO_MPLS)) {
include/net/protocol.h:int inet6_add_protocol(const struct inet6_protocol *prot, unsigned char num);
➜ linux git:(master)
|