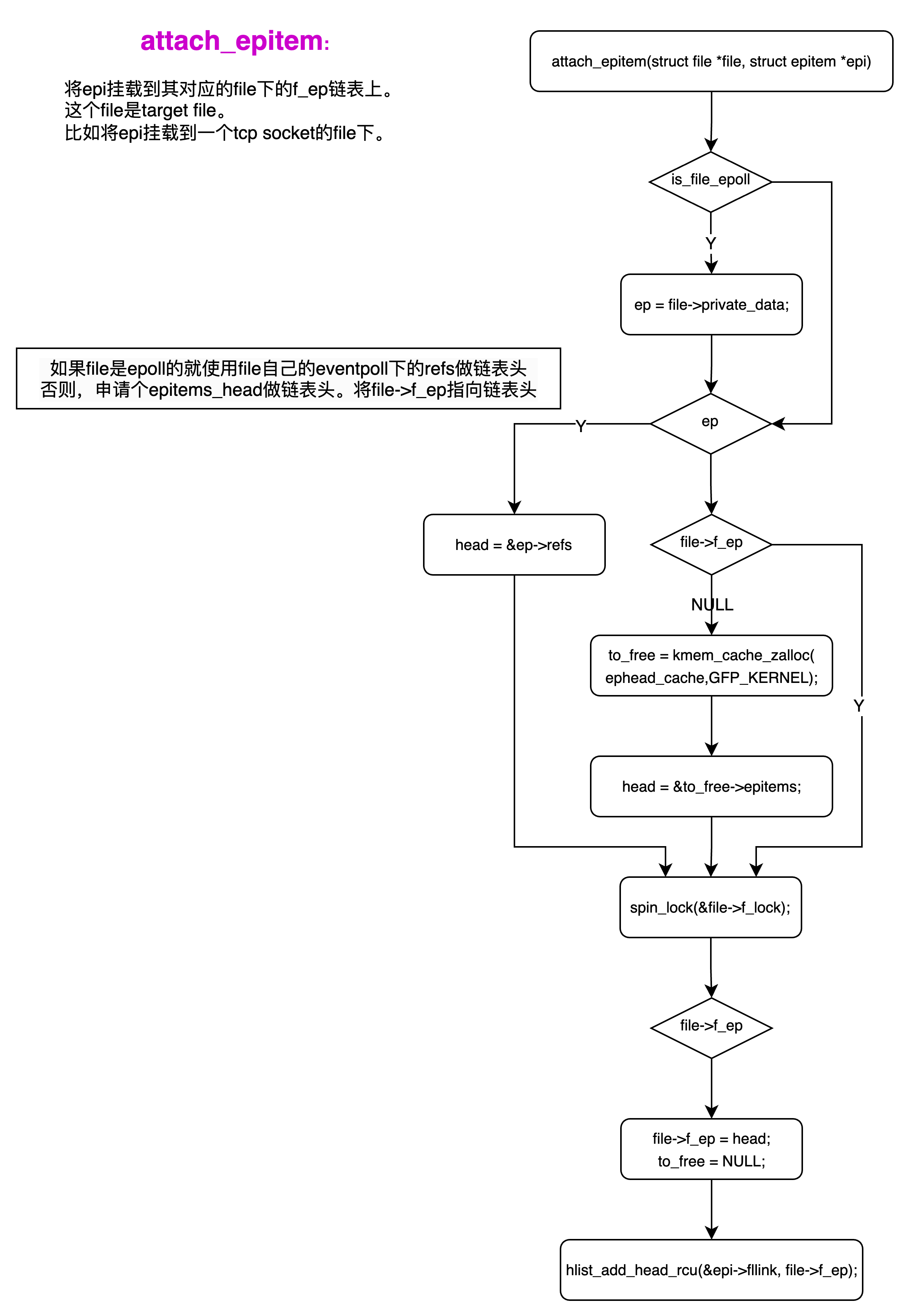
问题现象
tcpdump/iproute2 是很多网络问题下的调试工具,大家也都很熟他的一些特性。比如,
- 执行tcpdump命令后,如果没有使用
-p参数, 网口会进入PROMISC状态。 - 通过ip link命令可以查看网口状态,其中状态位里有个
PROMISC标志。
但是,后台执行一个在 eth0 口上抓包的tcpdump命令,就会发现一个问题:
- 当tcpdump命令在后台运行时,通过查看
ip link结果,对应网口的状态标志位没有PROMISC标志位,也没有其他变化。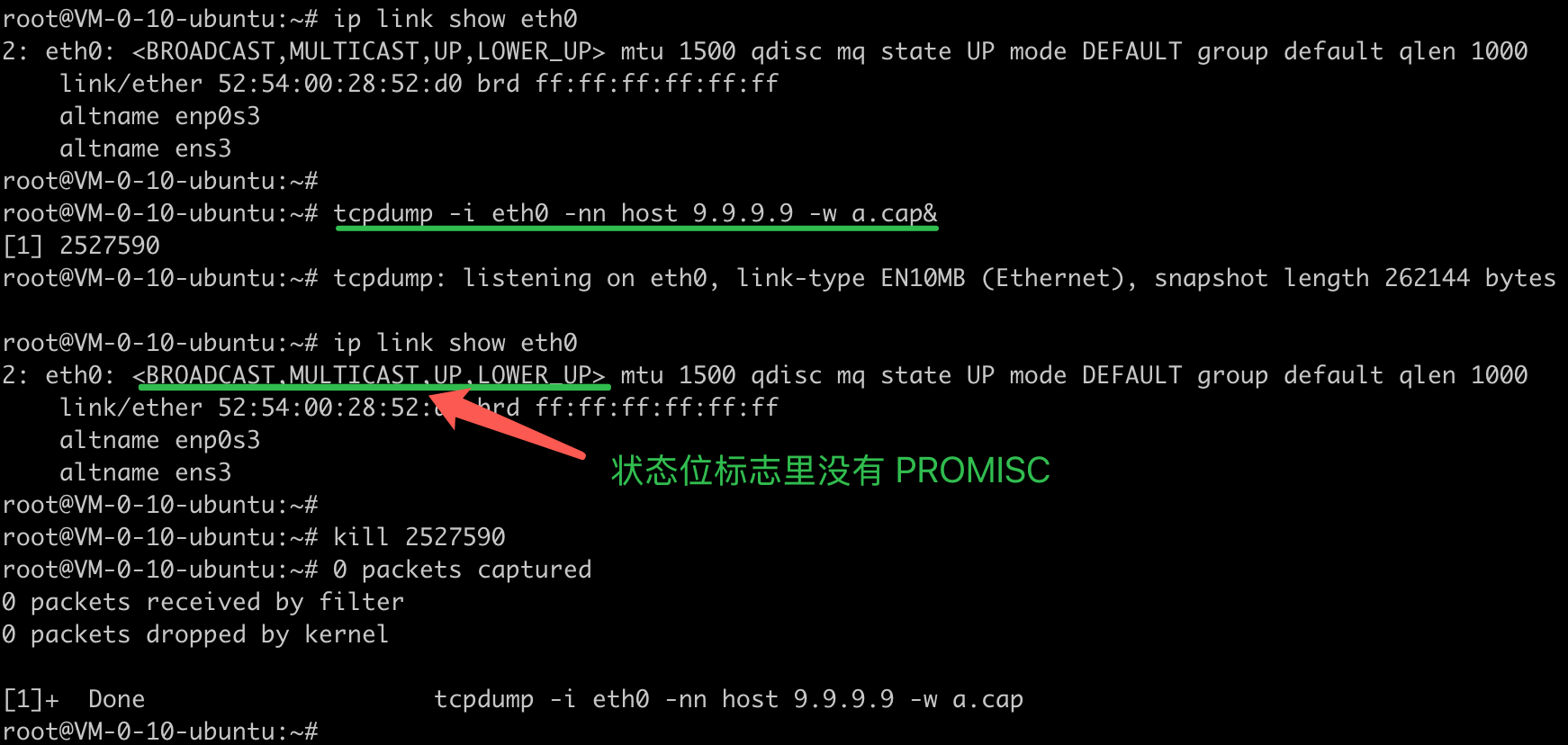
为了避免干扰,关闭tcpdump 后,我们又做了另外一个验证操作。
- 执行
ip link set dev eth0 promisc on命令,设置网口混杂模式。这时,网口的PROMISC标志位能正常显示出来。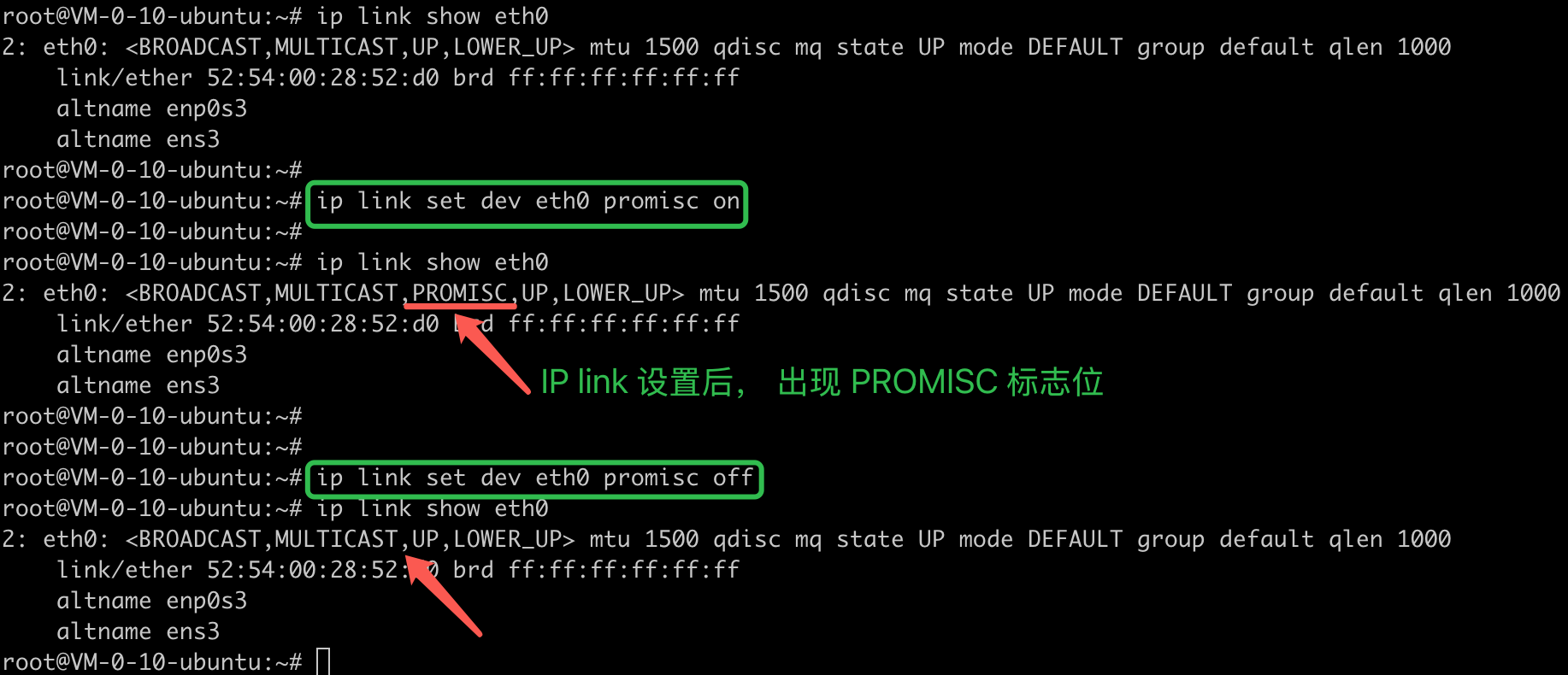
这样看来,PROMISC标志位只受ip link命令控制,与在网口上是否运行tcpdump无关。
看到这里,不免就有疑问了
- Q1: tcpdump执行时候,对应网口到底进没进入
PROMISC混杂模式呢?
A:进入PROMISC状态了。 因为对应时间段里,dmesg内核日志有明确的记录。
1 | [5828194.373058] virtio_net virtio0 eth0: entered promiscuous mode |
注意,ip link 命令设置 on 的时候,网口也会进入PROMISC混杂模式。
- Q2: 既然tcpdump和 iplink都能使网口进入混杂模式,这两个命令又可以独立执行。运行tcpdump命令抓包时,被ip link命令设置了
promisc off, 网卡会退出混杂模式,会不会对tcdpump抓包造成影响?
A:命令可以并发执行,不会相互干扰。这个场景下,ip link不会让网口退出混杂模式,也不会影响后续的 tcpdump 抓包。promisc off命令只会让 ip link 显示的网口的状态标志位里的PROMISC被清除掉。 - Q3: 多个tcpdum并行抓包,退出有先后,会不会相互影响?
A: 并行tcpdump执行,不会影响网口PROMISC。内核有引用计数机制,保证最后一个 tcpdump 退出时候,网口也跟着关闭混杂模式。