mysql访问延迟问题分析
问题背景
收到数据库同学的问题排查的请求,
同一个数据中心里,dbproxy到mysql的连接失败率偏高,其tcp connect调用的超时时间是20ms+。
分析过程
通过tcpdump在两端服务器上抓包,
发现
tcpdump抓包数据
1
2
3
4
| (缺另外一侧数据)
2017-04-27 16:01:09.403569 IP 100.69.103.13.50969 > 100.69.110.11.3306: Flags [S], seq 3051956561, win 14600, options [mss 1460,sackOK,TS val 1801758554 ecr 0,nop,wscale 7], length 0
2017-04-27 16:01:09.430687 IP 100.69.110.11.3306 > 100.69.103.13.50969: Flags [S.], seq 3148283284, ack 3051956562, win 14480, options [mss 1460,sackOK,TS val 3143621189 ecr 1801758554,nop,wscale 7], length 0
|
TCPDUMP数据分析
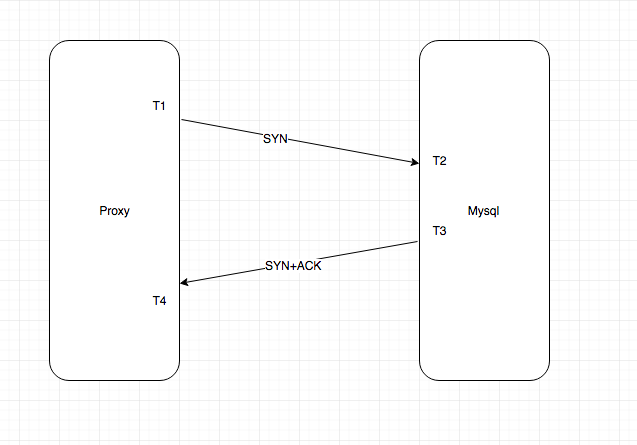
四个时间点分别即为t1,t2,t3,t4:
- t1: syn报文在clieint端抓取的时间
- t2: syn报文在server端抓取的时间
- t3: syn+ack报文在server端抓取的时间
- t4: syn+ack报文在client端抓取的时间
观察发现两类case:
t1 比t2早20ms+, 而t2, t3, t4的时间点相差不到2ms- t4 比
t3晚20ms+, 而t1, t2, t3的时间点相差不到2ms
因为我们的服务器上都部署了ntp服务,所以服务器之间的时间偏差控制的非常好,可以保证偏差在1ms左右(甚至更低)。
所以上面的四个时间点可以认为以同一个时间轴上的。
因次,可确定是报文数据被延迟了。
该问题不是出现在单台服务器上,mysql的好多台服务器都存在不同程度的延迟。
因此延迟的怀疑对象有:
- 物理传输网络(交换机及网线)
- 服务器
根据历史经验判断交换机丢包的可疑点最大,因此找交换机同学寻求帮助,并建议进行交换机上的端口镜像抓包。
交换机网络排查
网络的同学提供了一个很好的检测工具,hping。
通过hping我们可以很容易的判断单台服务器是否存在报文延迟。
期间经过网络同学的尝试,得到一些测试信息(包含了同学们的血泪史):
- 数据库mysql服务停止,问题依然存在。
- 更换服务器端的网线,问题依然存在。
- 更换tor交换机的上联网线,问题依然存在。
- 使用装机模板重新安装服务器,问题消失。
- 重装后的服务器启用老的内核和网卡驱动,问题消失。
- reboot服务器,问题消失
- 最终通过端口镜像,锁定该问题不是物理传输网络的问题,重新回到服务器端进行排查。
服务器端问题排查
因为我们最开始的排查时候,已经使用tcpdump命令,锁定了这个问题是网络报文传输延迟。
现在排除服务器端网络报文延迟的可能后,
因为tcpdump抓包位置是在内核协议栈的入口netif_receive_skb里,通过ptye_all这个钩子链表,
捕获到报文的,整个过程是在内核软中断(确切说是RX softirq)里做的,
因此可以排除应用程序的干扰的可能。
最值得怀疑的是:
那么接下来的任务及时进一步锁定排查的范围,
首先从软硬件的角度去排查:
我们出问题的机器上使用的网卡是intel的x540万兆网卡, 硬件和驱动在圈里的口碑很不错的。
为此我们也跟intel的网卡同学进行了沟通,
尽管我们服务器上的网络配置存在瑕疵,但是不足以导致出现有1ms以上的报文延迟。
受限于我们没有复现问题的手段,我们只能够从目前出问题的10+台服务器身上寻找突破。
同时,之前的排查也表明,这个问题在服务器重启之后就会消失,而且无法复现。
HPING测试结果再分析
我们手头的测试数据除了tcpdump,就只有hping测试结果可用,
因此只能在hping测试结果上,做文章。
测试结果里出现了最大19ms+的延迟,
1
| len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251230 win=0 rtt=19.2 ms
|
这是一个hping的测试结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| [mailto:root@gs-event2-mysql04.gz01:~$]root@gs-event2-mysql04.gz01:~$ !gre
grep 251230 -B 100 -C 20 B --color
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251294 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251295 win=0 rtt=0.0 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251296 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251297 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251298 win=0 rtt=0.0 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251299 win=0 rtt=0.0 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251300 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251301 win=0 rtt=0.0 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251302 win=0 rtt=0.0 ms
....(为方便讨论省略部分记录)
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251391 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251392 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251393 win=0 rtt=0.0 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251394 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251395 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251396 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251397 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251398 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251230 win=0 rtt=19.2 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251239 win=0 rtt=18.2 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251249 win=0 rtt=17.2 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251244 win=0 rtt=17.7 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251266 win=0 rtt=15.2 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251259 win=0 rtt=16.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251288 win=0 rtt=12.8 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251277 win=0 rtt=14.0 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251355 win=0 rtt=5.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251362 win=0 rtt=4.3 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251373 win=0 rtt=3.0 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251384 win=0 rtt=1.7 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251390 win=0 rtt=1.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251399 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251400 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251401 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251402 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251403 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251404 win=0 rtt=0.0 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251405 win=0 rtt=0.1 ms
len=46 ip=100.69.110.41 ttl=64 DF id=0 sport=0 flags=RA seq=251406 win=0 rtt=0.0 ms
|
把出问题的前100个和后20个报文打印,我们发现
只是部分报文被延迟,其他报文是正常的。
打印下各个报文的, 发现序列号每增加1个,延迟大概降低100us,正好匹配发包时间间隔。
1
2
3
4
5
6
7
8
9
10
11
12
| 序列号 延迟ms
1 251230 19.2
2 251239 18.2
3 251249 17.2
4 251244 17.7
5 251266 15.2
6 251259 16.1
7 251288 12.8
8 251277 14.0
9 251355 5.1
10 251362 4.3
11 251373 3.0
|
相对第一个报文的序列号偏移, 延迟差值
1
2
3
4
5
6
7
8
9
10
| 1 9 -1
2 19 -2
3 14 -1.5
4 36 -4
5 29 -3.1
6 58 -6.4
7 47 -5.2
8 125 -14.1
9 132 -14.9
10 143 -16.2
|
通过上面分析我们可以确定:
- 网络有问题:
部分报文被延迟了
- 网络没问题:
不是全部报文被延迟
哈哈哈,部分报文被延迟了, 但是不是全部报文.
寻找被延迟的报文
根据hping的分析,我们看到部分报文被延迟了,那么接下来需要排查下这个延迟是什么时候发生的,如果能够得到问题现场,
缩小排查的范围(比如硬件问题, 驱动问题,或者其他)。
经过考虑,设计一个测试场景,
1
2
3
4
| 1 启用hping报文的时间戳(timestamp)选项,让hping报文携带上client段的时间点(单位ms),
2 在服务器端(tcp server)增加一个直接编写的网桥KO,
3 网桥KO,检查hping报文的时间点跟服务器内核里的`tcp timestamp`的偏移
4 如果时间偏移超过预设值(10ms+),那么可以判定该报文已经产生延迟了。
|
通过新编写的内核网桥测试模块, 我们获取到了出问题时候,内核的一些场景信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| 1 Pid: 6579, comm: ss Not tainted 2.6.32-573.18.1.el6.toav2.x86_64 #1
2 Call Trace:
3 [] ? netdev_frame_hook+0x183/0x1ac [hook]
4 [] ? __netif_receive_skb+0x1c7/0x570
5 [] ? netif_receive_skb+0x58/0x60
6 [] ? napi_skb_finish+0x50/0x70
7 [] ? napi_gro_receive+0x39/0x50
8 [] ? ixgbe_clean_rx_irq+0x26a/0xc70 [ixgbe]
9 [] ? ixgbe_poll+0x40a/0x760 [ixgbe]
10 [] ? net_rx_action+0x103/0x2f0
11 [] ? __do_softirq+0xc1/0x1e0
12 [] ? tick_program_event+0x2f/0x40
13 [] ? call_softirq+0x1c/0x30
14 [] ? do_softirq+0x65/0xa0
15 [] ? irq_exit+0x85/0x90
16 [] ? smp_apic_timer_interrupt+0x4a/0x60
17 [] ? apic_timer_interrupt+0x13/0x20
18 [] ? s_show+0x1ad/0x330
19 [] ? s_show+0xa7/0x330
20 [] ? seq_read+0x289/0x400
21 [] ? proc_reg_read+0x7e/0xc0
22 [] ? vfs_read+0xb5/0x1a0
23 [] ? fget_light_pos+0x16/0x50
24 [] ? sys_read+0x51/0xb0
25 [] ? system_call_fastpath+0x16/0x1b
|
这里搜集到两个有用的信息:
- 出问题的时候都是在ss命令的上下文里。
- 出问题的时候都是在每个cpu的本地时钟中断里,而不是网卡中断里。
这两个信息对我们后续的排查起了很大的引导作用。
SS命令的尝试
- 跟数据库同学协调,在一个停了服务的机器上,删除了ss命令,问题消失。yeah!
因为断定SS命令会是问题的触发点。
期间,根据intel同学的建议,把网卡的亲和性做了调整,关闭掉irqbalance,发现问题依然存在。
但是问题出现的频率有所降低。
- 根据出问题时候,cpu的调用栈没有在网卡中断的handler里,判定要么网卡中断被阻塞(关闭了),
要么是网卡本身就没有产生中断。
期间进行如下实验,但是失败了。
尝试使jprobe去抓取网卡中断去处理函数失败。
- 怀疑下半部被禁止了, 抓取bh的enable和disable的调用时间,未见异常。
- 不停的跑ss命令20+分钟,未能复现问题。
- 猜测这个问题是某个cpu出问题,卡顿了一下。同时,ss命令又跟问题触发条件相关。
进行了一个实验:
- 把ss运行的核跟网卡中断的核分割开,1问题消失了。ss不再导致报文延迟了。
- 反向试验,ss命令强制跟网卡中断在一个cpu上,问题必现。
后续的测试试验,使用ss命令跟cpu在一个核上。
走弯路,掉进INET_DIAG坑里
ss命令是用来dump 内核里的tcp的链接的。
其使用tcp diag和inet diag连个模块,通过netlink跟内核进行交互,
从而获取内核里的tcp socket的状态。
查看两个ko的代码,发现有基础bh相关的操作。
这是怀疑跟bh有关系, 虽然之前bh统计未见异常(疑神疑鬼哈哈哈——)
把tcp diag和inetdiag重新加载,问题仍然存在
把tcp diag 和inet diag重新编译,并加入debug,发现bh前后工作很正常
结合网桥debug未发现异常
再次分析SS命令
下载ss命令代码,研究ss命令的实现
发现关闭ss所有tcp socket dump的功能后,问题依然存在。
最后把一个不起眼的读/proc/slabinfo的操作关闭后,问题消失了!!!
编写一个单独的程序读取/proc/slabinfo的程序,
发现一旦读的数据超过特定长度12000+,问题基本必现,只是延迟大小有些不同而已。
/PROC/SLABINFO分析
分析内核/proc/slabinfo代码发现, 其实现的代码里正好跟网桥debug时候输出的调用s_show重合。
其s_show的函数里会执行关闭irq的操作。
写一个内核debug ko,模拟了s_show做相同的操作,成功复现了ss相同的现象。报文延迟20+ms
1
2
3
4
5
6
| 1 show_kmem_cache: 1494580765:721875 <--- 1494580765:723446, ext4_inode_cache: node0, full:16612, partial:22, free:0
2 show_kmem_cache: 1494580765:726766 <--- 1494580765:728612, dentry: node0, full:18756, partial:72, free:0
3 show_kmem_cache: 1494580765:729015 <--- 1494580765:732834, radix_tree_node: node0, full:29923, partial:10315, free:0
4 show_kmem_cache: 1494580765:733024 <--- 1494580765:738746, radix_tree_node: node1, full:995, partial:39315, free:0
5 show_kmem_cache: 1494580765:738960 <--- 1494580765:757472, buffer_head: node0, full:48009, partial:148216, free:0
6 show_kmem_cache: 1494580765:758144 <--- 1494580765:815435, buffer_head: node1, full:1143, partial:402863, free:0
|
感谢隔壁老王对这个问题的技术指导,感谢数据库和网络兄弟团队的支持。