11 /**
12 * __struct_group() - Create a mirrored named and anonyomous struct
13 *
14 * @TAG: The tag name for the named sub-struct (usually empty)
15 * @NAME: The identifier name of the mirrored sub-struct
16 * @ATTRS: Any struct attributes (usually empty)
17 * @MEMBERS: The member declarations for the mirrored structs
18 *
19 * Used to create an anonymous union of two structs with identical layout
20 * and size: one anonymous and one named. The former's members can be used
21 * normally without sub-struct naming, and the latter can be used to
22 * reason about the start, end, and size of the group of struct members.
23 * The named struct can also be explicitly tagged for layer reuse, as well
24 * as both having struct attributes appended.
25 */
26 #define __struct_group(TAG, NAME, ATTRS, MEMBERS...) \
27 union { \
28 struct { MEMBERS } ATTRS; \
29 struct TAG { MEMBERS } ATTRS NAME; \
30 } ATTRS
```
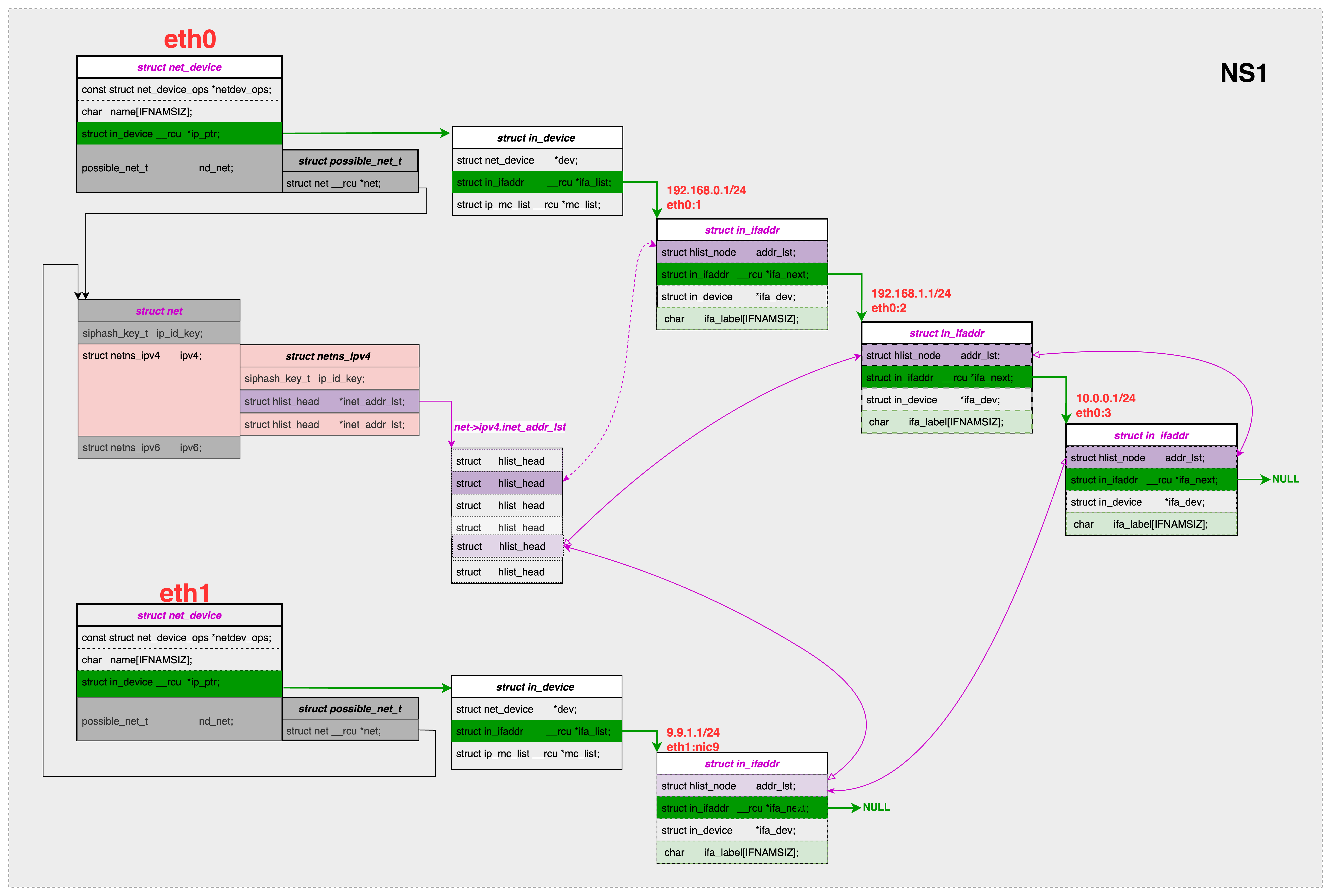
[root@VM-0-12-centos ~]# ip a show dev lo 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet 9.9.9.199/24 scope global lo:9 valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever
52 struct inet6_protocol { 53 int (*handler)(struct sk_buff *skb); 54 55 /* This returns an error if we weren't able to handle the error. */ 56 int (*err_handler)(struct sk_buff *skb, 57 struct inet6_skb_parm *opt, 58 u8 type, u8 code, int offset, 59 __be32 info); 60 61 unsigned int flags; /* INET6_PROTO_xxx */ 62 };