总结
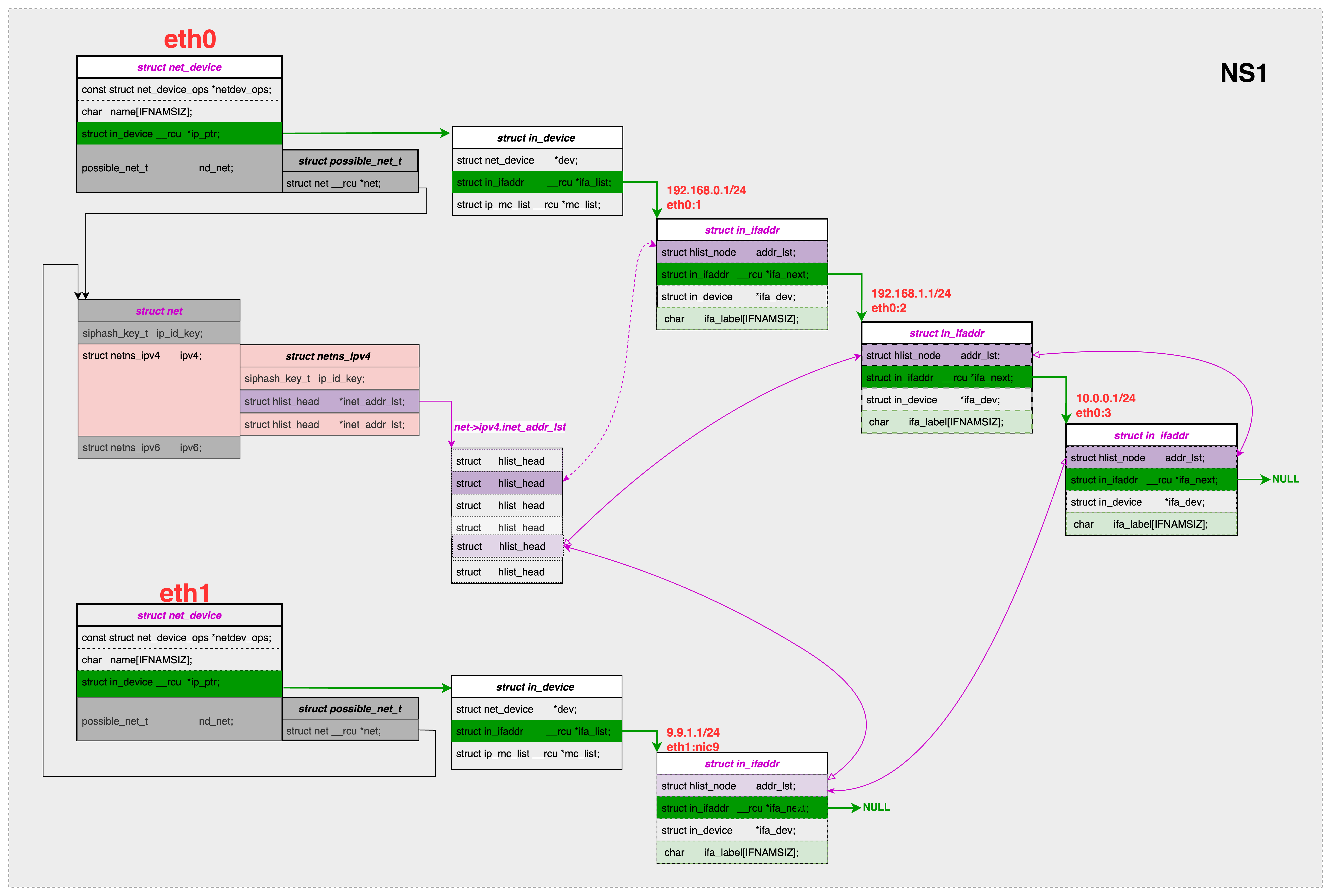
内核如何管理 网口上的IPv4 地址:
- 每个网口下面有多个IPv4地址,每个IP地址存放到一个
struct in_ifaddr的结构体里。这个结构体里存放别名、ip地址和掩码信息。 - 每个网口下面有一个单链表,每个ifa 节点通过
ifa_next指向下一个 ifa 节点。通过这个链表把多个 ifa 地址链接在一起。 - 每个 net_namespace下有多个网口,通过一个 hash 数据链表(
net->ipv4.inet_addr_lst),把各个网口下的全部ifa节点,放到这个hash链里面。hash值相同的 ifa 节点,通过addr_list挂在到一个hash 桶下。 - 别名并不会创建一个独立的网口,只是在同一个网口下增加一个对应的 ifa结构体并挂载到上面的两个链表中。跟通过ip link 命令给一个网口增加一个地址相同,唯一不同在于这个地址起了一个别名或者叫label。
命令行操作
有时候我们需要给一个网口配置的多个 IP 地址,这时候我们有两种配置方法:
- 使用 ifconfig 配置到网口别名上。
- 使用 ip addr 命令直接配置到网口上。
两种方法最终在内核实现是一样的,存储位置也一样,并且可以相互读写配置结果。
比如将9.9.9.199/24配置到 lo 口上,并起个别名lo:9
1 | [root@VM-0-12-centos ~]# ifconfig lo:9 9.9.9.199/24 |
ifconfig命令的配置结果,也可以通用ip link命令来查看
1 | [root@VM-0-12-centos ~]# ip a show dev lo |
网口的别名在ip命令里被当做label输出,放在scope字段后面